Datenkonzept - von den Rohdaten zur Visualisierung
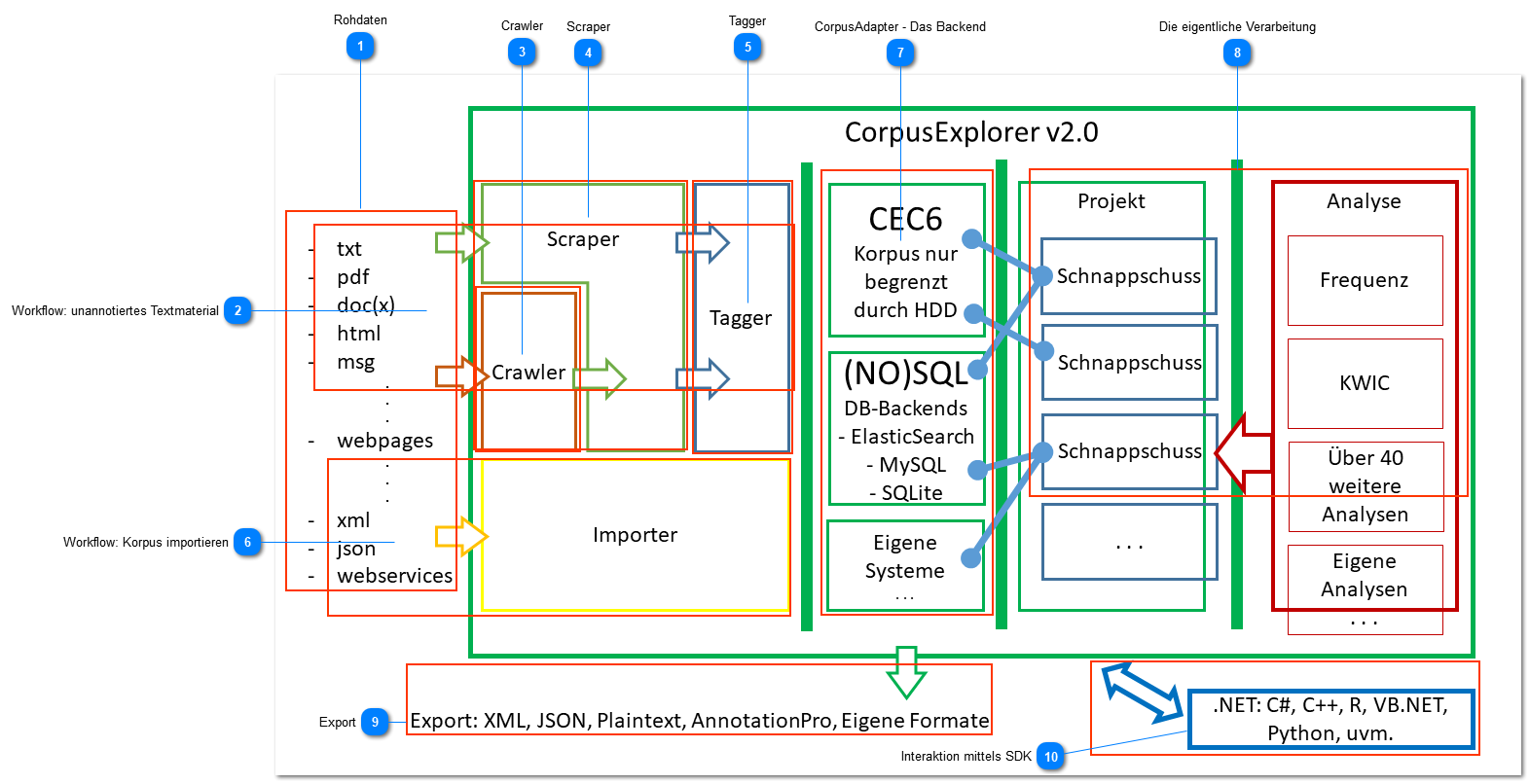
Im Folgenden geht es darum, wie der Datenverarbeitungsprozess im CorpusExplorer strukturiert ist.
Rohdaten
Der CorpusExplorer verarbeitet eine Vielzahl von Rohdaten - aktuell werden über 100 Datenformate unterstützt. Der Quellcode ist frei verfügbar (OpenSource) auf GitHub https://github.com/notesjor/corpusexplorer2.0 - Die Formate sind in einzelne Projekte ausgelagert. Alle Projekte mit externen Formate beginnen mit CorpusExplorer.Sdk.Extern. gefolgt vom jeweiligen Format z. B. XML - also: CorpusExplorer.Sdk.Extern.Xml oder CorpusExplorer.Sdk.Extern.Json
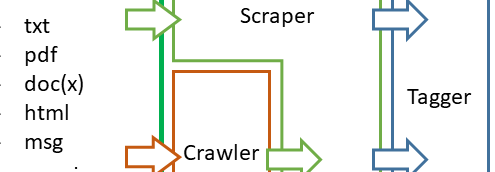
Crawler sind Programme/Komponenten, die Texte/Daten von Webseiten automatisch extrahieren können. Der CorpusExplorer verüfgt über eigene Crawler zur Akquise von Web-Korpora.
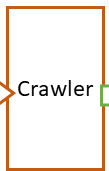
Scraper (vom engl. scrape -> kratzen) sind Komponenten, die aus Dateien oder Webseiten (daher umschließt der Scraper den Crawler) Texte und Metadaten extrahieren können. Um eigene Scraper zu programmieren, erben Sie von der Klasse AbstractScraper - ggf. gibt es vereinfachtere Klassen in den jeweiligen externen Programmbibliotheken (siehe CorpusExplorer.Sdk.Extern. ---) z. B. CorpusExplorer.Sdk.Extern.Xml > AbstractXmlDocumentScraper
Alle Tagger im CorpusExplorer werden von der Klasse AbstractTagger abegeleitet. Tagger sind für die Zerteilung in Sätze, Token und die Annotation zuständig.
Daten die bereits annotiert wurden, können über einen Importer direkt in den CorpusExplorer übernommen werden. Dies entspricht in der GUI der Funktion "Korpus importieren". Falls Sie eine eigenen Importschnittstelle programmieren möchten, dann leiten Sie diese von AbstractImporter oder AbstractImporterSumple3Steps ab.
Egal wie die Daten in den CorpusExplorer gelangen, am Ende werden diese immer in einem Backend gespeichert. Dabei handelt es sich um eine recht komplexe Struktur. Der Aufwand um einen Scraper (siehe 4) zu programmieren beläuft sich auf wenigen Minuten, einen Importer (siehe 6) zu programmieren auf Stunden bis Tage. Für die Programmierung eines Backends sollten Sie mehrere Tageb bis 1-2 Wochen einplanen. Für ein Backend müssen Sie drei Klassen implementieren:
AbstractCorpusAdapter - Diese Klasse verwaltet die Metadaten und die Layer und stellt grundlegende Funktionalitäten bereit.
AbstractLayerAdapter - Diese Klasse verwaltet die jeweiligen Dokument-Layer.
AbstractCorpusBuilder - Diese Klasse nimmt die Daten von Taggern/Importern engegen und erstellt CorpusAdapter und LayerAdapter
Folgende Backends stehen zur Verfügung - Ein bestehende Corpus kann über die statische Funktion Create(string path) geladen werden - z. B. CorpusAdapterWriteDirect.Create("C:/corpus.cec6"):
CorpusAdapterWriteDirect - Dies ist das aktuell Standardformat des CorpusExplorers. Dateien mit diesem Format enden auf *.cec6 - Die gesamte Datei wird in den Arbeitsspeicher engelsen. Maximale Korpusgröße durch verfügbaren Arbeitsspeicher begrenzt.
CorpusAdapterWriteIndirect - Hierbei handelt es sich um das gleiche Datenformat wie bei CorpusAdapterWriteDirect (CEC6) - mit dem Unterschied, dass nur die Referenzen und Metadaten in den Arbeitsspeicher geladen werden. Die eigentlichen Dokumentdaten werden erst bei Bedarf und dann nur temporär geladen. Dadurch können wesentlich größere Korpora bei geringer Arbeitsspeicherbelastung geladen werden. Der Datenzugriff wird durch Festplattenzugriffe verlangsamt.
CorpusAdapterSingleFile - Dies ist das veraltete CEC5-Format.
CorpusAdapterElasticSearch - Die Daten werden in ElasticSearch (NoSQL-Datenbank basierend auf Lucene-Volltextindex) gespiechert. Extrem gut skalierbare Datenbank (horizontal und vertikal skalierbar). Unbegrenzte Korpusgröße.
CorpusAdapterLinqConnect - Nutzt MySQL zum Speichern von Korpusdaten - unbegrenzte Korpusgröße. MySQL ist weit verbreitet, aber gerade bei großen Datenmengen nur schwer zu optimieren. Verwenden Sie besser ElasticSearch.
CorpusAdapterLinqConnect - Nutzt SQLite zum Speichern von Korpusdaten. SQLite eignet sich eigentlich nur für kleinere bis mittlere Korpora, da es sich bei SQLite um eine integrierte Datenbank handelt. Dafür kann SQLite auf Mobilgeräten genutzt werden. Die Installation eine Datenbanksoftware wie bei MySQL oder ElasitcSearch ist nicht notwendig.
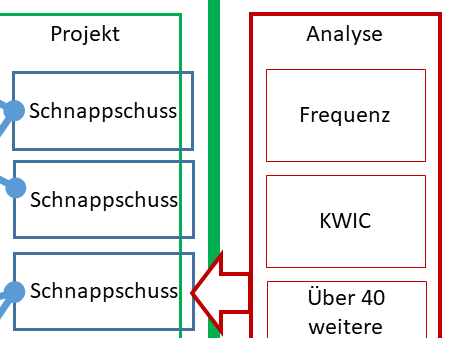
Der CorpusExplorer unterstützt vielfältge Exportformate. Sowohl für die Korpusdaten als auch für Analyseergebnisse.
Wenn Sie eigene Exporter bauen möchten, dann leiten Sie diese bitte von folgenden Klassen ab:
AbstractExporter - Basisklasse für den Export in andere Korpusformate.
AbstractTableWriter - Basisklasse für den Export von Analyseergebnissen, die als Tabelle vorliegen. Verfügbar aktuell z. B.: CSV, HTML, JSON, SQL, TSV und XML
Der CorpusExplorer erlaubt es durch ein SDK (Software Development Kit) und die konsequente OpenSoruce-Strategie dieses Projekts - mit anderen Programmen zu interargieren. Sie hierzu auch "Die Software-Entwickler-Ecke".