Der Autosplit ist eine überraschen mächtige Funktion. Sie können damit den CorpusExplorer anweisen eigenständig, anhand von Metadaten, neue Schnappschüsse zu erstellen.
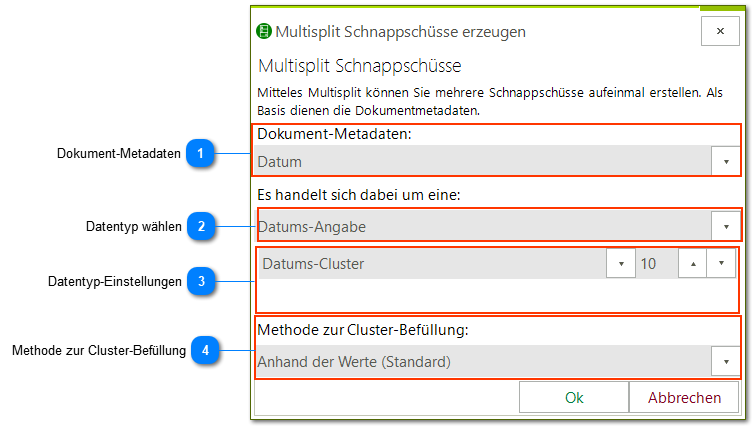
Dokument-Metadaten
Wählen Sie hier die Metadatenangabe aus, die für den Autospilt herangezogen werden soll.
Sie können z. B. in einem Zeitungskorpus den Verlag oder den Autor wählen, um Unterschiede zu untersuchen.
Geben Sie an, wie die Daten zu interpretieren sind. Je nach Angabe verändern sich die Optionen unter 3.
Folgende Datentypen können gewählt werden:
Text-Information / Wertbasierte Information - Für jeden Wert wird ein eigenes Schnappschuss erstellt. Ideal wenn Sie z. B. unter Dokument-Metadaten Autoren-, Genre- oder Verlagsdaten auswählen.
Ganzzahl-Cluster - Interpretiert die Daten als Ganzzahl, sortiert diese und teilt diese in gleich große Cluster (siehe hierzu 4 - Methode zur Cluster-Befüllung).
Kommazahl-Cluster - Interpretiert die Daten als Kommazahl, sortiert diese und teilt diese in gleich große Cluster (siehe hierzu 4 - Methode zur Cluster-Befüllung).
Datums-Angabe - Stellt unter 3 besondere Segmentierungswerkzeuge für Datumsangaben bereit.
Die hier gezeigten Einstellungen sind abhängig vom gewählten Datentyp (siehe 2). Folgende Einstellungen gibt es für die jeweiligen Datentypen:
Text-Information / Wertbasierte Information
Keine Optionen - Für jeden Wert wird ein eigener Schnappschuss erstellt.
Ganzzahl-Cluster
Wieviele Cluster benötigen Sie - Geben Sie an, wieviele Cluster Sie benötigen. Wie diese befüllt werden, ist abhängig von der "Methode zur Cluster-Befüllung" - siehe 4.
Kommazahl-Cluster
Wieviele Cluster benötigen Sie - Geben Sie an, wieviele Cluster Sie benötigen. Wie diese befüllt werden, ist abhängig von der "Methode zur Cluster-Befüllung" - siehe 4.
Datums-Angabe
Datums-Cluster - ähnlich Ganzzahl/Kommazahl-Cluster nur auf Basis von Datumsangaben
Identisch Datum/Uhrzeit - Für jede unterschiedliche Datums-/Uhrzeit-Angabe wird ein eigener Schnappschuss erstellt.
Jahr/Monat/Tag/Stunde/Minute - Minutengenaue Unterscheidung bei der Schnappschussbildung.
Jahr/Monat/Tag/Stunde - Stundengenaue Unterscheidung bei der Schnappschussbildung.
Jahr/Monat/Tag - Unterscheidung bei der Schnappschussbildung auf Basis von Tagesangaben.
Jahr/Monat - Unterscheidung bei der Schnappschussbildung auf Basis von Monatsangaben.
Jahr - Unterscheidung bei der Schnappschussbildung auf Basis von Jahresangaben.
Jahrzehnt - Unterscheidung bei der Schnappschussbildung auf Basis von Jahrzenten (basierend auf Schnitt in der Datumangabe): Bsp. 2018 > 201
Jahrhundert - Unterscheidung bei der Schnappschussbildung auf Basis von Jahrhunderten (basierend auf Schnitt in der Datumangabe): Bsp. 2018 > 20
Wenn Sie ein Cluster erstellen, müssen Sie die "Methode zur Cluster-Befüllung" wählen. Folgende Auswahlmöglichkeiten stehen zur Verfügung:
Anhand der Werte - Sortiert zunächst die Werte. Ermittelt den höchsten (MAX) und niedriegsten (MIN) Wert. Daraus ergibt sich ein Bereich (MAX - MIN), der durch die Anzahl der Cluster geteilt wird [(MAX - MIN) / Cluster]. Die einzelnen Bereich definieren die jeweilige Wert-Grenze. Bsp. Min = 10 / Max = 110 / Cluster = 10 (110 - 10) / 10 = 10 Cluster 1 => 10 bis 20 / Cluster 2 => 20 bis 30 ... Cluster 10 => 100 bis 110
Gleiche Anzahl an Dokumenten - Sortiert zunächst die Werte. Danach wird die entsprechende Anzahl an Clustern gebildet. In der Reihenfolge der sortierten Werte werden dann die Dokumente auf die Cluster verteilt. Sobald ein Cluster die maximale Anzahl an Dokumenten enthält, wird der darauf Cluster befüllt. Der erste Cluster enthält demnach die Dokumente mit den niedrigsten Werten. Der letzte Cluster die Dokumente mit den höchsten Werten.
Ähnlicher Umfang - Sätze (näherungsweise) - Sortiert zunächst die Werte. Danach wird die entsprechende Anzahl an Clustern gebildet. In der Reihenfolge der sortierten Werte werden dann die Dokumente auf die Cluster verteilt. Sobald ein Cluster die maximale Anzahl an Sätzen überschreitet, wird der darauf Cluster befüllt. Der erste Cluster enthält demnach die Dokumente mit den niedrigsten Werten. Der letzte Cluster die Dokumente mit den höchsten Werten.
Ähnlicher Umfang - Token (näherungsweise) - Sortiert zunächst die Werte. Danach wird die entsprechende Anzahl an Clustern gebildet. In der Reihenfolge der sortierten Werte werden dann die Dokumente auf die Cluster verteilt. Sobald ein Cluster die maximale Anzahl an Token überschreitet, wird der darauf Cluster befüllt. Der erste Cluster enthält demnach die Dokumente mit den niedrigsten Werten. Der letzte Cluster die Dokumente mit den höchsten Werten.
Hinweis: Es wird immer ein zusätzlicher REST-Schnappschuss gebildet. Dieser kann leer sein oder überzählige Dokumente enthalten.