Dokumente annotieren
Diese Anleitung erklärt, wie Sie aus Text-Dateien (auch PDF, MSWord, RTF, etc.) ein Korpus erstellen können.
Voraussetzung:
-
Sie haben den CorpusExplorer gestartet - [CorpusExplorer starten]
Vorbemerkung:
-
Wenn Sie Dateien mit unterschiedlichem Dateityp haben, z. B. HTML-Seiten, PDF-Dokumente und E-Mails, dann können Sie diese nicht zusammen in ein Korpus packen. Wiederholen Sie den Vorgang mit jedem Dateityp. Sie erhalten so mehrere Korpora (3 im Bsp.). Diese können Sie dann gemeinsam in einem Projekt analysieren.
Anleitung - via Korpusmenü:
-
Klicken Sie auf "Dokumente annotieren" (2)
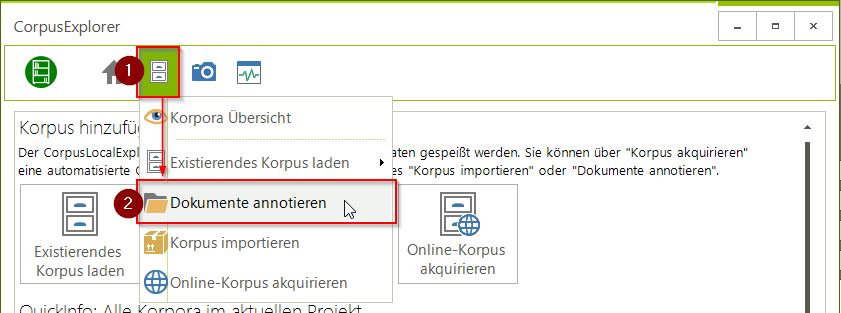
-
Der folgende Dialog erscheint - Hier ist es wichtig, dass Sie zuerst den Dateityp auswählen (1). Hinweis: Es werden nur die gewählten Dateitypen angezeigt die auf den in diesem Schritt ausgewählten Filter passen.
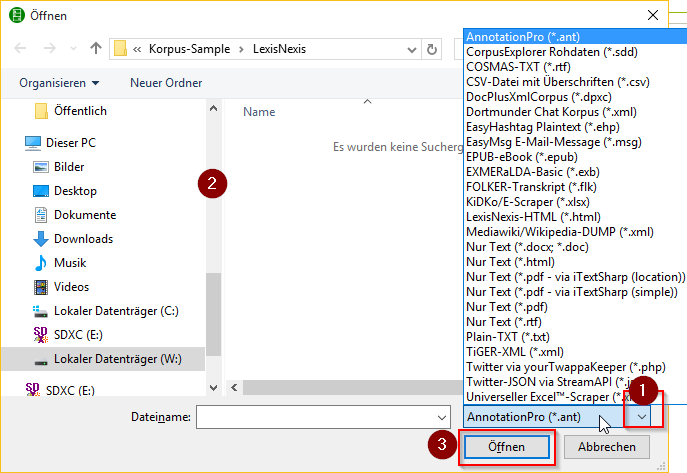
-
Wählen Sie dann den Ordner und dann die Dateien (2) aus und klicken Sie abschließend auf Öffnen (3).
-
Durch das das Drücken der Tastenkombination STRG + A bzw. CTRL + A werden alle Dateien im Ordner ausgewählt. Halten Sie die STRG- bzw. CTRL-Taste gedrückt während Sie auf eine Datei klicken um diese an- bzw. abzuwählen. Bei der hier dargestellten Dateiauswahl handelt es sich um das Standardvorgehen zur Dateiauswahl unter Windows.
-
Wenn Sie mit der Auswahl zufrieden sind, klicken Sie auf "Öffnen" - (s.o. bei 3)
-
Nach einiger Zeit werden die gefundenen Dokumente angezeigt (s.u.). Wurden keine Dokumente gefunden, dann brechen Sie den Vorgang bitte ab und versuchen Sie es ggf. mit einem anderen Dateityp-Filter. Nebensächlich: In diesem Dialog sehen Sie links den Volltext, rechts die Metadaten. Über dem Text sehen Sie zwei grüne Pfeile, mit denen Sie durch die Texte navigieren können. Aktuell ist Text 1 von 600 gewählt. Selektiv können Sie auch einen/mehrere Texte ignorieren.
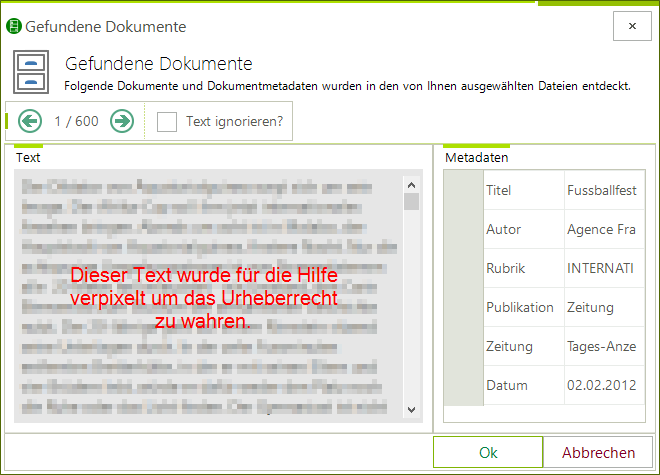
-
Klicken Sie im Dialog auf "OK" um zum nächsten Schritt zu gelangen.
-
In diesem Dialog können Sie den Tagger auswählen, der zur automatischen Aufbereitung genutzt werden soll. Die Standardsprache ist immer "Deutsch" - wenn ihr Korpusmaterial in einer anderen Sprache vorliegt, dann klicken Sie bitte auf "Erweiterte Einstellungen" und wählen die gewünschte Sprache. Hinweis: Die verfügbaren Sprachen hängen von Tagger ab und nicht vom CorpusExplorer. Einige Tagger erlauben auch einen anderen Installationsort, bzw. verfügen über zusätzliche Optionen. Hinweis (für Softwareentwickler*innen): Mithilfe des CorpusExplorer.SDK können Sie eigene Tagger entwickeln oder bestehende Tagger in den CorpusExplorer integrieren.
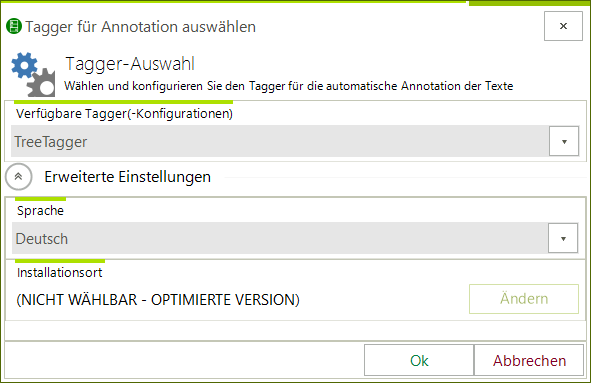
-
Im letzten Schritt müssen Sie noch einen eindeutigen Namen für das Korpus vergeben. Unter diesem Namen wird das Korpus automatisch nach der Erstellung gespeichert. Klicken Sie nach der Vergabe auf "OK".
-
Der Tagging-Prozess startet - je nach Umfang dauert dies ein paar Minuten. Sobald der Prozess abgeschlossen ist, wird das Korpus automatisch geladen.
Folgende Dateiformate und Tagger stehen zur Verfügung:
Annotierbare Dateiformate (Basis)
APAEK-Unterrichtstranskript (*.pdf)|*.pdf
AnnotationPro (*.ant)
CLARIN ContentSearch CSV-Export (*.csv)
CorpusExplorer Rohdaten (*.sdd)
COSMAS-TXT (*.rtf)
CSV-Datei mit Überschriften (*.csv)
DocPlusXmlCorpus (*.dpxc)
Dortmunder Chat Korpus (*.xml)
D-Spin Slash/A (*.xml)
DTA-Basisformat (*.tcf.xml)
EasyHashtag Plaintext (*.ehp)
EPUB-eBook (*.epub)
EXMERaLDA-Basic (*.exb)
FOLKER-Transkript (*.flk)
KiDKo/E-Scraper (*.xlsx)
LexisNexis-HTML (*.html)
Mediawiki/Wikipedia-DUMP (*.xml)
Nur Text (*.docx; *.doc)
Nur Text (*.html)
Nur Text (*.pdf - via iTextSharp (location))
Nur Text (*.pdf - via iTextSharp (simple))
Nur Text (*.pdf)
Nur Text (*.rtf)
Plain-TXT (*.txt)
PostgreSQL-XML-Dump (*.xml)|*.xml
TiGER-XML (*.xml)
Twitter via yourTwappaKeeper (*.php)
Twitter-JSON via StreamAPI (*.json)
Twitter-Status-JSON via SearchAPI (*.json)|*.json
Universeller Excel-Scraper (*.xlsx)
WebLicht-XML (*.xml)
WET-Format http://commoncrawl.org (*.warc.wet)|*.warc.wet
Annotierbare Dateiformate (mit zusätzlichen Add-ons)
Add-on: Apache Tika
Auf gut Glück mit Apache Tika (*.*)
Add-on: Toxy
Auf gut Glück mit Toxy (*.*)
Add-on: Pandoc
PANDOC [commonmark] (*.txt; *.*)
PANDOC [docbook] (*.docbook; *.xml; *.*)
PANDOC [Microsoft Word] (*.docx)
PANDOC [epub] (*.epub)
PANDOC [haddock] (*.txt; *.*)
PANDOC [html] (*.html)
PANDOC [json] (*.json)
PANDOC [LaTeX] (*.tex; *.latex; *.*)
PANDOC [markdown] (*.txt; *.*)
PANDOC [markdown - github] (*.txt; *.*)
PANDOC [markdown - mnd] (*.txt; *.*)
PANDOC [markdown - phpextra] (*.txt; *.*)
PANDOC [markdown - strict] (*.txt; *.*)
PANDOC [wikipedia / mediawiki] (*.txt; *.*)
PANDOC [native] (*.txt; *.*)
PANDOC [OpenOffice / LibreOffice] (*.odt)
PANDOC [opml] (*.opml; *.*)
PANDOC [org] (*.txt; *.*)
PANDOC [rst] (*.rst; *.*)
PANDOC [t2t] (*.t2t; *.*)
PANDOC [textile] (*.txt; *.*)
PANDOC [twiki] (*.txt; *.*)
Verfügbare Tagger
Basis-Tagger
Keine Annotation - Nur Textimport
TreeTagger
TreeTagger (ohne Phrasen / höhere Performance)
TreeTagger (eigenes Skript)
TnT-Tagger
UDPipe (eigene/externe Installation)
Tagger Add-ons
MarMoT
OpenNLP (Percepton)
OpenNLP (Maxent)
Stanford POS
UDPipe
Verfügbare Backends
Verfügbare Backends (Basis)
CorpusExplorer v6
CorpusExplorer (EchtzeitEngine)
CorpusExplorer v5
Verfügbare Backends (mit zusätzlichen Add-ons)
ElasticSearch
MySQL
SQLite
APAEK-Unterrichtstranskript (*.pdf)|*.pdf
AnnotationPro (*.ant)
CLARIN ContentSearch CSV-Export (*.csv)
CorpusExplorer Rohdaten (*.sdd)
COSMAS-TXT (*.rtf)
CSV-Datei mit Überschriften (*.csv)
DocPlusXmlCorpus (*.dpxc)
Dortmunder Chat Korpus (*.xml)
D-Spin Slash/A (*.xml)
DTA-Basisformat (*.tcf.xml)
EasyHashtag Plaintext (*.ehp)
EPUB-eBook (*.epub)
EXMERaLDA-Basic (*.exb)
FOLKER-Transkript (*.flk)
KiDKo/E-Scraper (*.xlsx)
LexisNexis-HTML (*.html)
Mediawiki/Wikipedia-DUMP (*.xml)
Nur Text (*.docx; *.doc)
Nur Text (*.html)
Nur Text (*.pdf - via iTextSharp (location))
Nur Text (*.pdf - via iTextSharp (simple))
Nur Text (*.pdf)
Nur Text (*.rtf)
Plain-TXT (*.txt)
PostgreSQL-XML-Dump (*.xml)|*.xml
TiGER-XML (*.xml)
Twitter via yourTwappaKeeper (*.php)
Twitter-JSON via StreamAPI (*.json)
Twitter-Status-JSON via SearchAPI (*.json)|*.json
Universeller Excel-Scraper (*.xlsx)
WebLicht-XML (*.xml)
WET-Format http://commoncrawl.org (*.warc.wet)|*.warc.wet
Annotierbare Dateiformate (mit zusätzlichen Add-ons)
Add-on: Apache Tika
Auf gut Glück mit Apache Tika (*.*)
Add-on: Toxy
Auf gut Glück mit Toxy (*.*)
Add-on: Pandoc
PANDOC [commonmark] (*.txt; *.*)
PANDOC [docbook] (*.docbook; *.xml; *.*)
PANDOC [Microsoft Word] (*.docx)
PANDOC [epub] (*.epub)
PANDOC [haddock] (*.txt; *.*)
PANDOC [html] (*.html)
PANDOC [json] (*.json)
PANDOC [LaTeX] (*.tex; *.latex; *.*)
PANDOC [markdown] (*.txt; *.*)
PANDOC [markdown - github] (*.txt; *.*)
PANDOC [markdown - mnd] (*.txt; *.*)
PANDOC [markdown - phpextra] (*.txt; *.*)
PANDOC [markdown - strict] (*.txt; *.*)
PANDOC [wikipedia / mediawiki] (*.txt; *.*)
PANDOC [native] (*.txt; *.*)
PANDOC [OpenOffice / LibreOffice] (*.odt)
PANDOC [opml] (*.opml; *.*)
PANDOC [org] (*.txt; *.*)
PANDOC [rst] (*.rst; *.*)
PANDOC [t2t] (*.t2t; *.*)
PANDOC [textile] (*.txt; *.*)
PANDOC [twiki] (*.txt; *.*)
Verfügbare Tagger
Basis-Tagger
Keine Annotation - Nur Textimport
TreeTagger
TreeTagger (ohne Phrasen / höhere Performance)
TreeTagger (eigenes Skript)
TnT-Tagger
UDPipe (eigene/externe Installation)
Tagger Add-ons
MarMoT
OpenNLP (Percepton)
OpenNLP (Maxent)
Stanford POS
UDPipe
Verfügbare Backends
Verfügbare Backends (Basis)
CorpusExplorer v6
CorpusExplorer (EchtzeitEngine)
CorpusExplorer v5
Verfügbare Backends (mit zusätzlichen Add-ons)
ElasticSearch
MySQL
SQLite